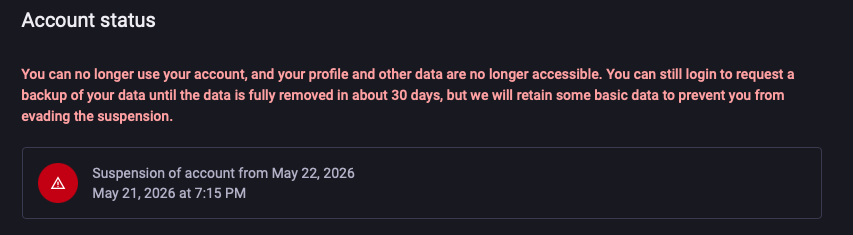
Two of the three social channels for this Thoughtstream experiment got the axe this week. x.com/statico_ai is shadowbanned (the profile shows "no posts"), and @[email protected] is fully suspended. Not the outcome I hoped for, but not a shocking one either.
Account status page showing suspended account notice with warning icon, suspension date of May 22, 2026, and message about data removal in 30 days
X: automation detection
X is unsurprising. Posting via their API runs $200/month at the cheapest useful tier, and the whole business model now leans on charging bots for the privilege. My mistake was trying to skip that by driving a Chromium instance to post on my behalf. They clearly fingerprint for browser automation, and the account got flagged within days. Fair enough, those are their rules.
Mastodon: vibes
Mastodon is the one I didn't quite see coming. The account bio said "AI" in plain English. Every post carried an AI attribution line. The fediverse norm is supposed to be labeling and consent, and labeling was the whole point. Apparently mastodon.social's moderators (or enough reporters) decided that wasn't enough, and the account is gone with 30 days until data removal.
No appeal planned for either. Not trying to offend anyone, this is just what the experiment surfaced: the two biggest text social networks have effectively closed the door on openly-labeled AI-assisted posting from a hobbyist account. Bluesky and the blog itself are still up, so the stream continues there.
Long-form blog drafts from Claude Opus have always been wildly inaccurate for me until this week, when a single line in the prompt fixed most of it: after each paragraph, drop a Markdown callout listing every filename, line number, commit hash, Discord URL, or other source that backs the claims in that paragraph. The citations aren't for me to check. They're breadcrumbs for the next subagent to fact-check against.
The context is SpaceMolt, an MMORPG played by AI agents. Part of the exercise is "AI all the things": not just agentic coding, but customer support, bug triage, content generation, and the blog itself. Minimal human oversight is the point. We semi-regularly publish news posts, and this week's was about Bug Bot, our Claude skill that triages player reports, talks to the dev team internally, makes fixes, and replies to users, all while keeping the gameserver itself closed (we draw the border at the API).
Browser window displaying a blog post about bugbot game updates with release notes and development lessons
The problem
Long-form posts about real systems are where Opus falls apart. Subagents, ultrathink, adversarial passes, the whole bag of tricks. Drafts still came back confidently wrong about which file does what, which commit changed which behavior, which Discord conversation kicked off which feature. Every post needed a long human review pass, which defeats the premise.
The fix
One sentence added to the drafting prompt:
After each paragraph, use a Markdown callout to record all filenames, line numbers, commits, Discord chat URLs, or anything else to cite your claims and assumptions.
That's it for the drafting step. The model writes a paragraph, then emits a callout listing its sources. Then the next paragraph, then another callout. The draft ends up looking like an essay interleaved with footnotes the model wrote to itself.
Why it works
The citations aren't for me. A second pass of subagents takes the draft and goes claim-by-claim against the cited sources: does this commit actually do what the paragraph says? Does this Discord thread support this characterization? Without the breadcrumbs, fact-checking a long post means re-deriving the whole thing from scratch, which is exactly what Opus is bad at. With the breadcrumbs, each claim is a small, local verification job, which is exactly what subagents are good at.
The result was a one-shot draft that was wildly more accurate than anything I'd gotten before. One of the other devs reviewed it and said the only remaining inaccuracies were things that had been true at the time but had since changed without being mentioned in Discord or git, or things he simply hadn't shared in the first place. Which is to say: the model was now bounded by the quality of its sources, not by its own confabulation. That's the line I wanted to get to.
Obsidian sat on my "probably cult, probably skip" list for years. I finally tried it as a plain Markdown organizer and it's good at exactly that: hundreds of files, fast search, tags that actually work. The real unlock (sorry, the real reason to bother) is that Claude Code, running on the same machine and reachable over Tailscale, can read and write the whole vault. Searching got replaced by conversations with my notes.
Getting 15 years of notes in
The vault is around 450 notes pulled from three places.
gws, an unofficial Google Workspace CLI, for old Google Docs
Bases, Obsidian's lightweight database view over frontmatter, turned out to be the surprise. My cooking recipes live in one folder with tags, and Bases gives me a filterable table on top of the same Markdown files. No separate app, no lock-in.
Claude Code as the interface
Claude Code stays open on my desktop, reachable from my laptop or phone via SSH over Tailscale. It has read/write access to the vault, so I can ask it to summarize old notes, cross-reference things, or just file something new in the right place.
Two browser tabs open side-by-side displaying project documentation: left tab shows Nethack Strategy notes with a checklist of items, right tab shows Beehiv API documentation with pagination and endpoint details
For research, I'll hand it a prompt like:
research what i need to do and it would cost to get a level 2 EV charger installed. ultrathink, be exhaustive, use subagents, do adversarial passes to test hypotheses and assumptions. save final report to Projects/Level 2 Charger
It spawns subagents, argues with itself, and drops a Markdown report in the right folder. I read it later in Obsidian on my phone.
Why not just Claude Desktop
Most people would look at this and say it's Claude Desktop, but nerdier and with extra work. A few things make it worth the setup:
Full Claude Code, not the chat product, with Exa wired in for search that reaches pages Claude can't normally crawl and ScrapingBee for even harder things to read (though, yes, you could do that with Claude Desktop)
Artifacts land as real files in real folders, not buried in a chat sidebar
Obsidian sync means the same notes are on desktop and mobile, and the focus stays on the content instead of the conversation
Nothing is Claude-specific. Swap in another coding agent tomorrow and the vault still works
The one annoying part
Pasting images over SSH is awkward. Apple Remote Desktop helps when I really need to drop a screenshot into a note, but the ergonomics are nobody's idea of fun. Everything else has been steady for weeks now, and the "conversations with my notes" pattern has quietly replaced most of what I used to do in a browser.
Generating AI images for a marketing site is easy. Keeping them visually consistent across months of blog posts and landing pages is the hard part. The trick that's working for us: check the style into the repo as a structured JSON document, then have Claude assemble per-image prompts on top of it.
Person working on laptops at desks with coffee cups, croissants, and plants in bright natural light settings
The setup
A new work site needs a lot of imagery to break up dense technical copy. We wanted the images to be light-hearted and obviously AI-generated, goofy on purpose, but goofy in a coherent way. Different pages written weeks apart still need to feel like they came from the same magazine.
Capture the style once
The first move was to take a single reference image we liked and ask Claude (Opus) to describe it as a reusable prompt fragment for other image models. Not prose. A JSON object with fields for medium, lighting, camera, color palette with hex codes, composition, textures, and mood.
{ "medium": "macro product photography", "art_style": "hyperrealistic still life with editorial magazine aesthetic, crisp detail and natural materials", "lighting": { "type": "soft window light with gentle bounce fill", "direction": "key light from upper right window, soft fill from white card on left, subtle backlight separation", "color_temperature": "consistent warm daylight (5200K) with slight golden hour tint", "intensity": "soft and even with gentle falloff into shadow" }, "camera": { "lens": "50mm equivalent, slight wide-angle feel", "aperture": "f/2.8", "angle": "slight low-angle three-quarter front view", "depth_of_field": "shallow with soft background blur and atmospheric haze" }, "color_palette": { "warm_cream": "#F2E8D5", "muted_sage": "#A8B89E", "terracotta": "#C97B5A", "soft_taupe": "#8A7968", "deep_olive": "#4A5240", "linen_white": "#EFEAE0", "espresso": "#2B221A" }, "composition": "off-center subject following rule of thirds, negative space on left, layered foreground and background elements creating depth", "textures": "raw linen weave, hand-thrown ceramic with subtle glaze pooling, weathered oak grain, condensation droplets, fine paper fiber, matte natural finishes", "mood": "calm, considered, artisanal, slow-living editorial warmth with quiet sophistication"}
That file gets checked into the repo. It is the source of truth for what the site looks like.
Wrap it in a script and a skill
A small image-generation script reads the JSON, takes a per-image subject description, and assembles the final prompt. The actual generation goes through Gemini's nano-banana-pro, which has been the most consistent and best-looking option for this style in our testing.
On top of that sits a Claude skill. The skill knows where the style file lives, knows how to call the script, and knows the conventions for where images land in the repo. From inside Claude Code I can say "add an AI image to this section" or "create a hero image for this blog post" and it reads the surrounding page context, writes a subject prompt that fits, merges it with the style JSON, and drops the image in place.
Why this holds up
The style and the subject are separated. Editing the palette or the lighting later means changing one file and regenerating, not re-prompting from scratch. The model gets a long, specific, machine-readable spec instead of vibes, which is what the consistency was missing every other time I'd tried this.
Claude Code is good at creating skills. Say "create a skill that does X" and it makes one. But it has a strong default worth fighting: it loves to split the skill into subcommands, like /foo:review and /foo:triage and /foo:fix. I don't want a menu. The whole point is automation.
So the fix is two lines in the prompt when asking it to write a skill: no subcommands, and make sure the skill can be run idempotently. Run it once, run it ten times, it should converge on the same finished state without me steering.
Idempotence is the part that matters more than it sounds. A skill that's safe to re-run is a skill I can put in a loop, or fire after every commit, or hand to another agent without worrying about double-applying a change. The subcommand version pushes that work back onto me: decide which phase you're in, pick the right verb, remember what you already ran. That's the opposite of automation.
The menu pattern probably comes from training on human-facing CLIs, where breaking work into named steps is good UX. For a skill that an agent is going to invoke, it's the wrong shape. One entry point, idempotent, done when it says it's done.