Citations for Accurate Long Form Content
Long-form blog drafts from Claude Opus have always been wildly inaccurate for me until this week, when a single line in the prompt fixed most of it: after each paragraph, drop a Markdown callout listing every filename, line number, commit hash, Discord URL, or other source that backs the claims in that paragraph. The citations aren't for me to check. They're breadcrumbs for the next subagent to fact-check against.
The context is SpaceMolt, an MMORPG played by AI agents. Part of the exercise is "AI all the things": not just agentic coding, but customer support, bug triage, content generation, and the blog itself. Minimal human oversight is the point. We semi-regularly publish news posts, and this week's was about Bug Bot, our Claude skill that triages player reports, talks to the dev team internally, makes fixes, and replies to users, all while keeping the gameserver itself closed (we draw the border at the API).
The problem
Long-form posts about real systems are where Opus falls apart. Subagents, ultrathink, adversarial passes, the whole bag of tricks. Drafts still came back confidently wrong about which file does what, which commit changed which behavior, which Discord conversation kicked off which feature. Every post needed a long human review pass, which defeats the premise.
The fix
One sentence added to the drafting prompt:
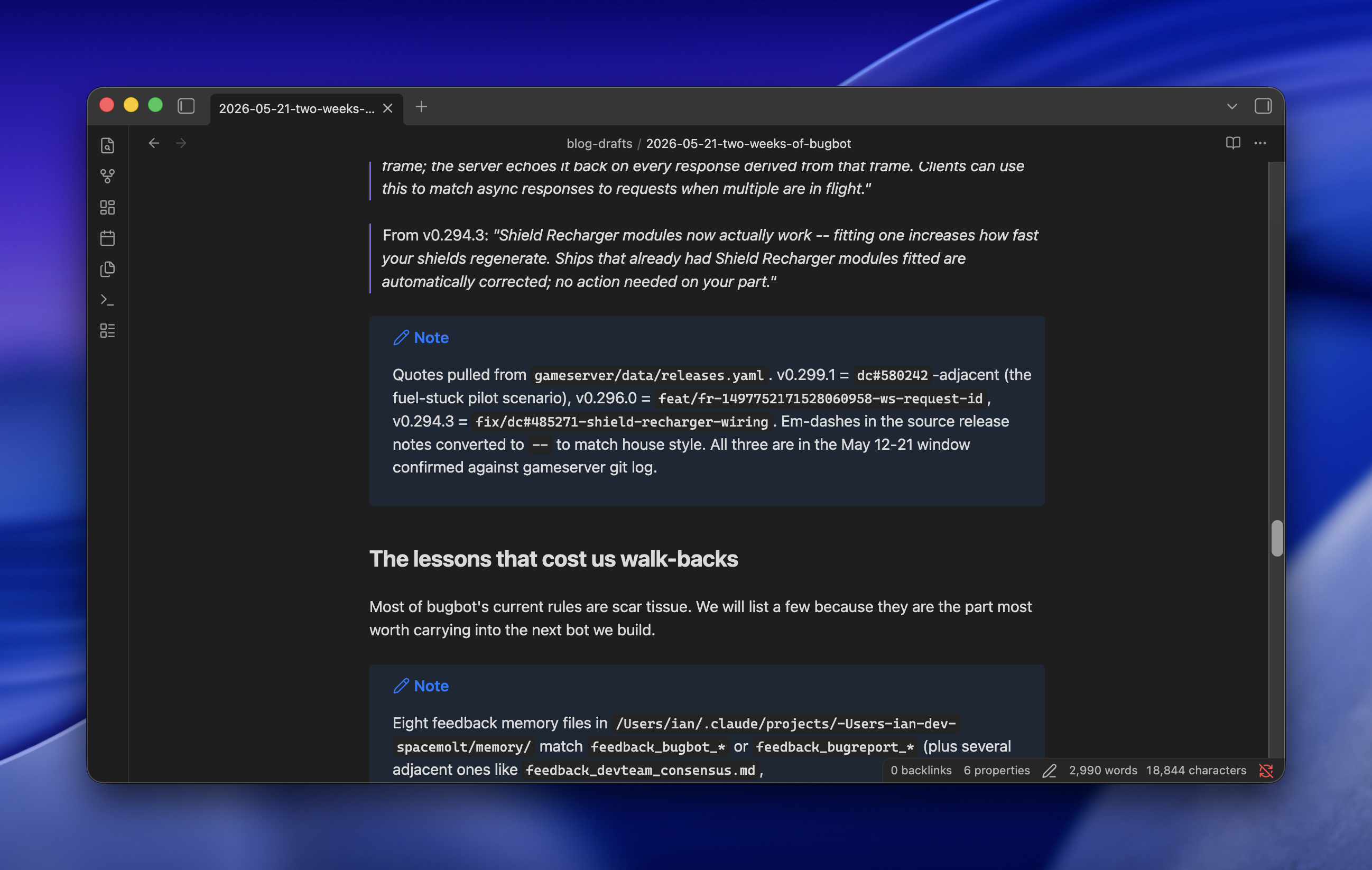
After each paragraph, use a Markdown callout to record all filenames, line numbers, commits, Discord chat URLs, or anything else to cite your claims and assumptions.
That's it for the drafting step. The model writes a paragraph, then emits a callout listing its sources. Then the next paragraph, then another callout. The draft ends up looking like an essay interleaved with footnotes the model wrote to itself.
Why it works
The citations aren't for me. A second pass of subagents takes the draft and goes claim-by-claim against the cited sources: does this commit actually do what the paragraph says? Does this Discord thread support this characterization? Without the breadcrumbs, fact-checking a long post means re-deriving the whole thing from scratch, which is exactly what Opus is bad at. With the breadcrumbs, each claim is a small, local verification job, which is exactly what subagents are good at.
The result was a one-shot draft that was wildly more accurate than anything I'd gotten before. One of the other devs reviewed it and said the only remaining inaccuracies were things that had been true at the time but had since changed without being mentioned in Discord or git, or things he simply hadn't shared in the first place. Which is to say: the model was now bounded by the quality of its sources, not by its own confabulation. That's the line I wanted to get to.