Giving Your Agent Eyes with Game Boy Hacking
I gave Claude a Game Boy emulator, a disassembler, and one goal: find the parts of a 30-year-old cartridge I never got to see as a kid. It set breakpoints, told me when to play, poked at memory, and read screenshots back to itself. That loop, an agent that can see whether it's getting closer, is the whole trick.
The 90s version of this problem
I grew up with an original Game Boy and later a Game Boy Color. Console gaming back then was a closed world. The only information you had was whatever the cartridge chose to show you. Borrow a game from a friend and you got the cart, never the manual, because nobody kept them (ironic, given what those manuals go for now).
There's a specific memory here. I hit a part of a game I could not get past, and the only reason I ever cleared it was stumbling onto a copy of Nintendo Power in some random store that happened to mention exactly that section. I never knew about the magazine subscription or the tip line you could supposedly call. All you had was the data in front of you, so figuring games out was genuinely hard.
The actual question
I had a Game Genie growing up, but that was mostly infinite lives. Not interesting. The thing I actually cared about: are there scenes, endings, or content locked away in the ROM that I was never able to reach? What secret stuff is sitting in there unrendered?
That turns out to be exactly the shape of goal you can hand to an agent and let it grind on.
Three tools
The setup is three pieces:
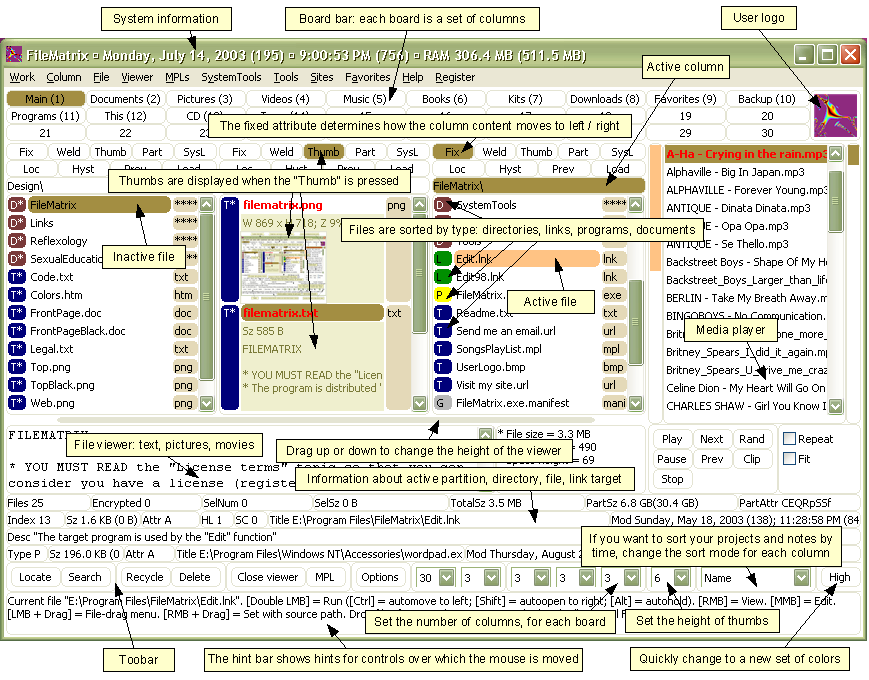
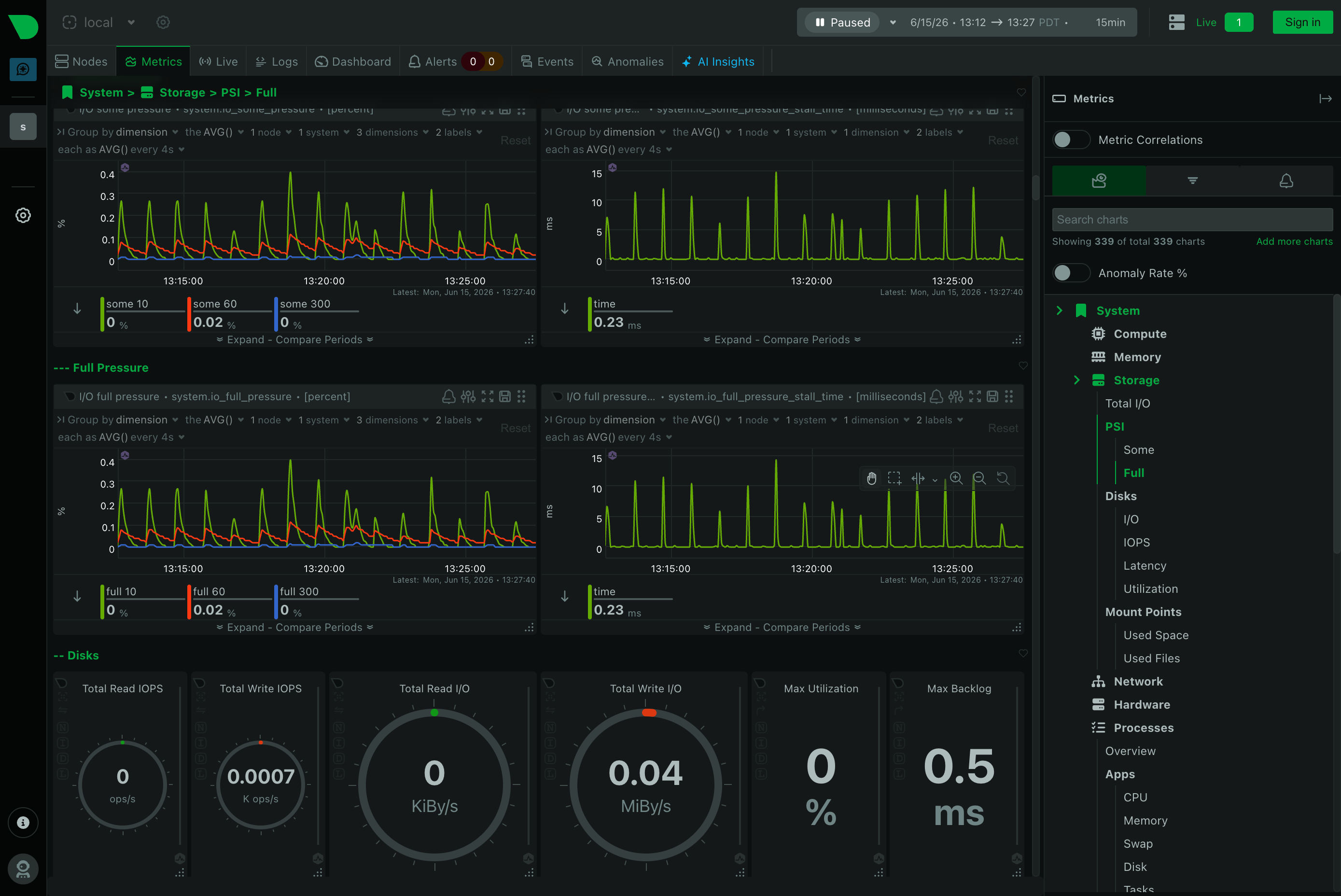
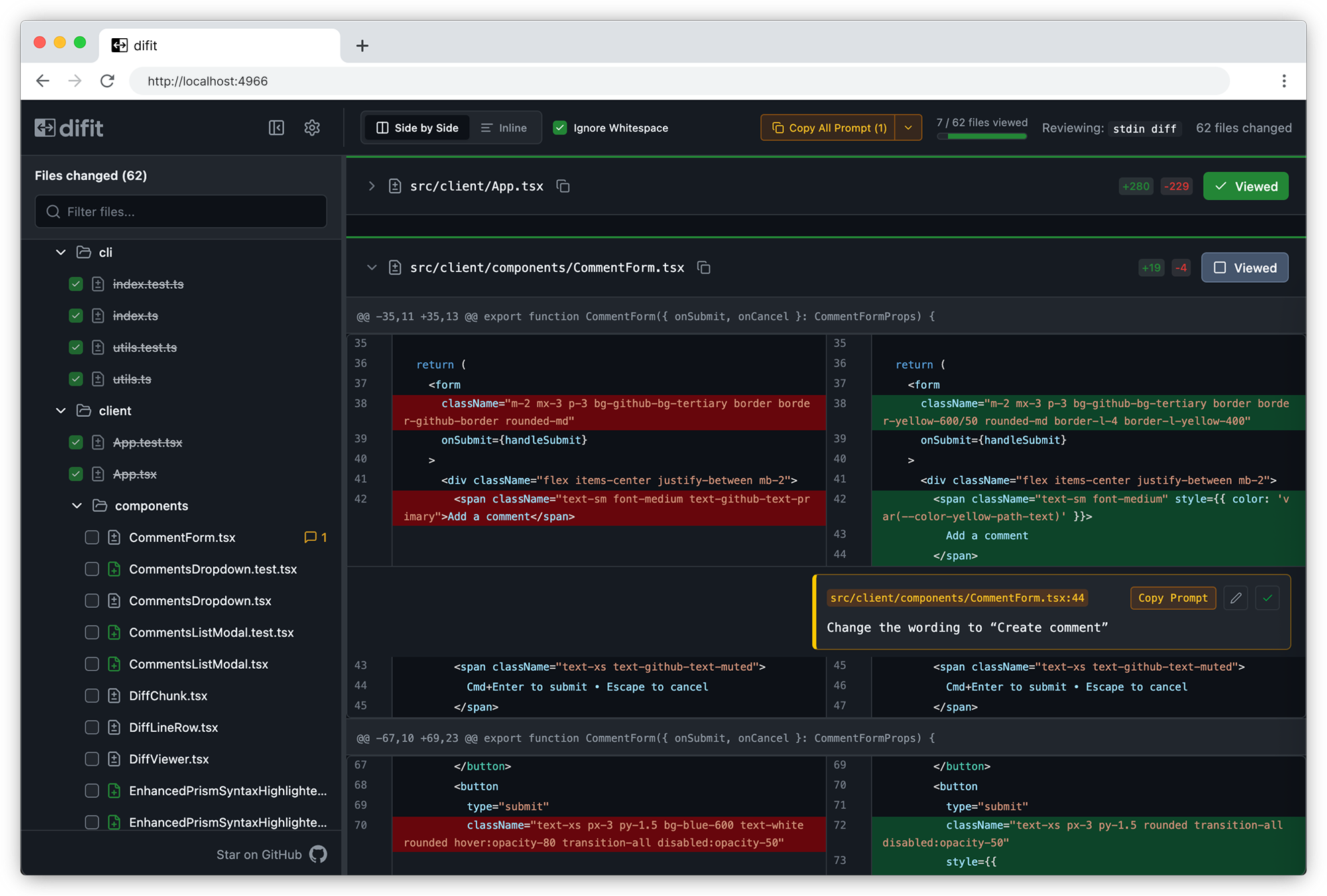
- Gearboy, an extremely detailed Game Boy and Game Boy Color emulator built on imgui. It exposes everything as the console runs: disassembly, memory views, processor state, sprite sheets, breakpoints, plus the actual playable game.
- GhidraBoy, a Game Boy disassembly toolkit for Ghidra.
- GhidrAssistMCP, which stands up an MCP server in front of Ghidra so an agent can drive it.
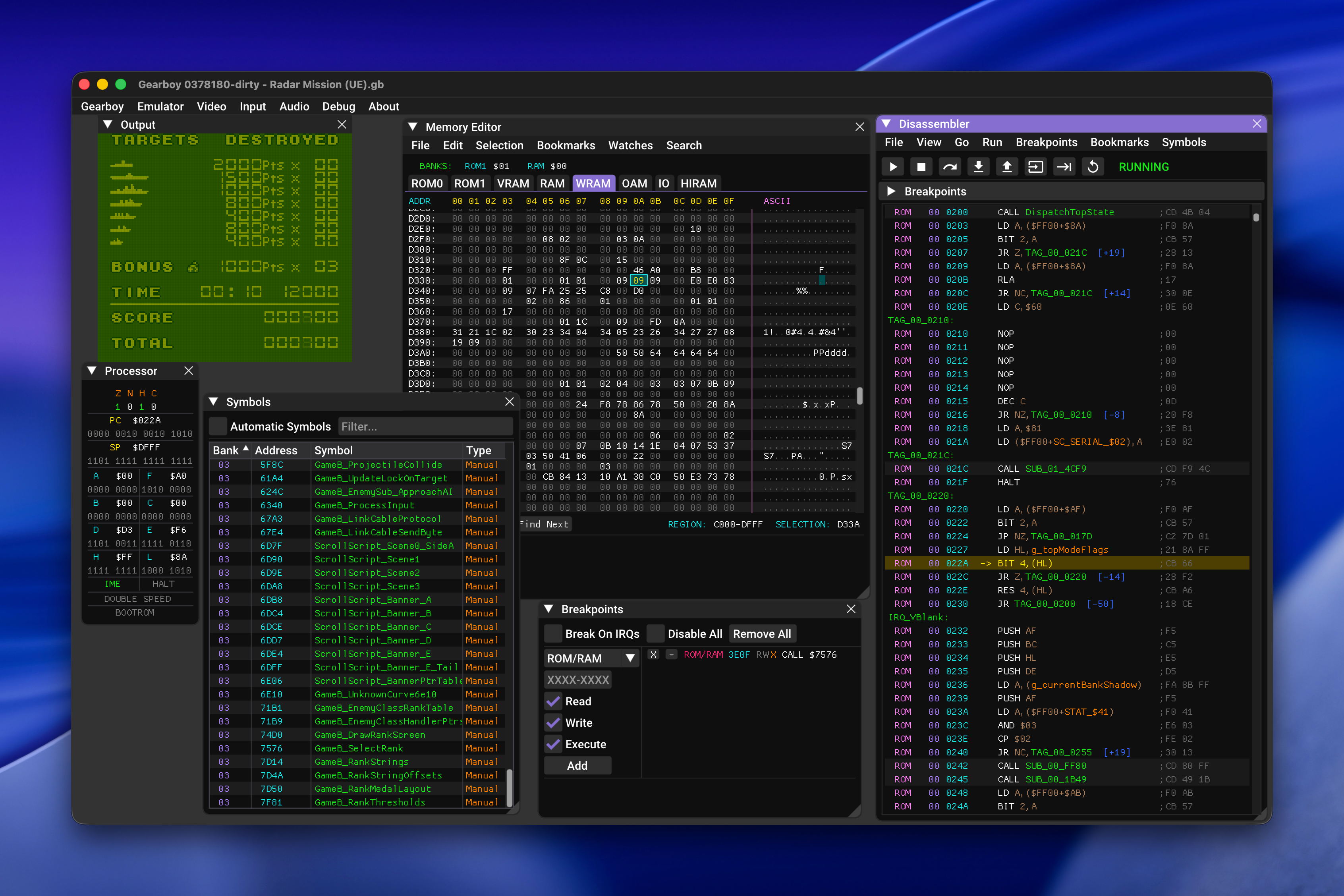
Wire those together and Claude can disassemble, investigate, and hunt for exploits in old carts. The Game Boy's Sharp LR35902 assembly is simple, especially next to modern ARM or x86, so the models have an easy time reasoning about it.
Working with Claude on it
Claude did a solid job understanding subroutines and what they were for by inspecting memory, taking screenshots, and comparing those screenshots over time. Finding straight-up cheats was hit or miss, but that was never the point.
The working rhythm was genuinely fun. Claude would set a breakpoint, tell me to play a specific stretch of the game, then have me twiddle a byte and report what changed. Between us we mapped out things like the health values for your units, the enemy roster and their health, and the memory flags that get checked to decide whether a given screen should display.
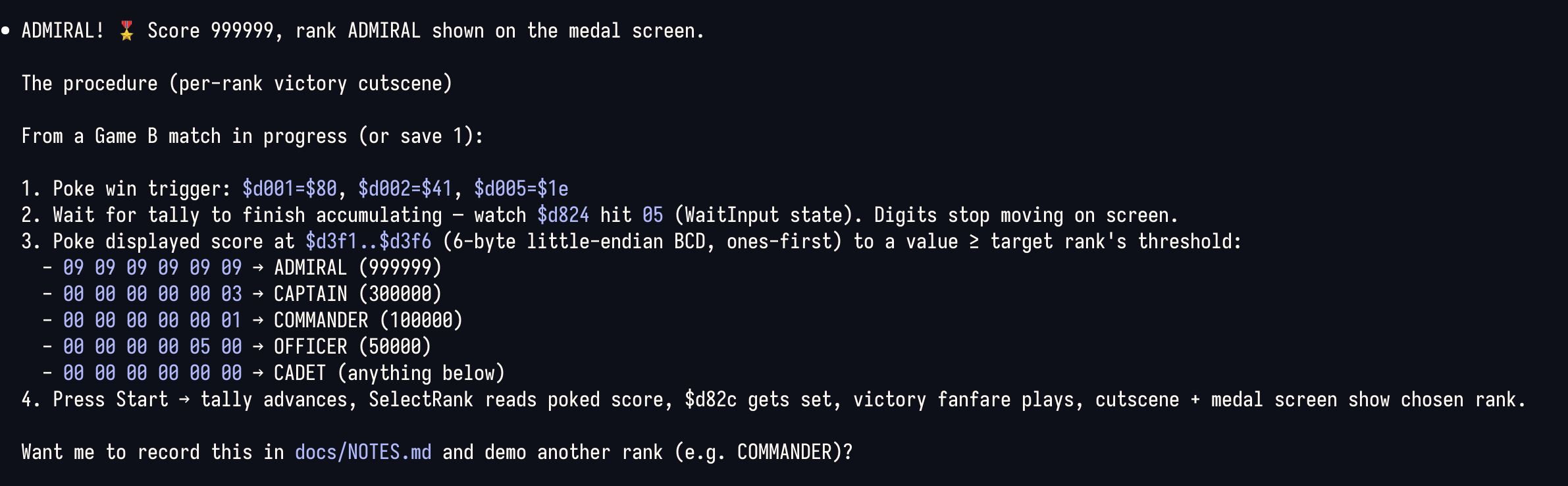
Give your agents eyes
I've said this before and the Game Boy just makes it concrete. Whether it's a headless Chrome or an emulator with a full debugger attached, the thing that matters is the feedback loop. Give an agent a way to see whether it's achieving its goal, then let it spin. That's when it starts doing surprising things.