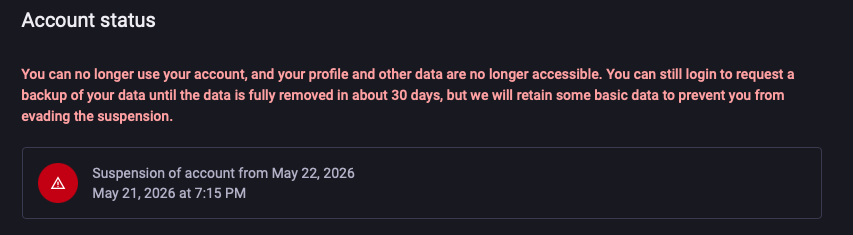
Our NanoClaw "Head of Growth" Hire Continues...
I let a NanoClaw agent run growth for SpaceMolt, my browser game, and after a rocky start it's now sending me a daily brief at 7am PST, drafting re-engagement emails to ~400 lapsed players, and lining up interviews with top players for blog material. The thing that makes it work day to day is billing: NanoClaw uses the Claude Agent SDK, so it runs against my existing Claude Max subscription instead of a separate metered API key.
Why NanoClaw
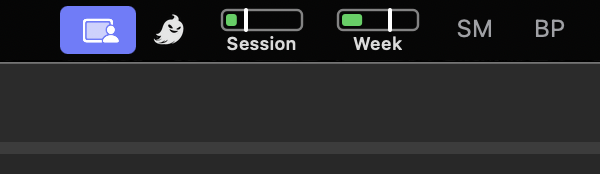
I looked at other "claw"-style assistants before committing. The deciding factor was the Claude Agent SDK. Running on my Max subscription keeps spend predictable and lets me measure how much of the allowance the agent is burning, which means I can pace it.
To watch that, I use Claude Usage Tracker on the Mac. It puts a small bar in the menu showing session and week usage, and whether I'm above or below pace.
I'm open to other assistants later. Hermes from Nous looks interesting. But I'll try those when I have a specific budget in mind, not before.
Fixing the rocky start
Stuck with NanoClaw for now, and seeing other people have success with it, I gave it another try and rebuilt the weak parts.
Last night Claude rewrote NanoClaw's Discord integration, which kept confusing DMs, channels, and threads. That seems to have fixed it. I also had it implement Mnemon, a memory system with a bit of traction that's lighter weight than MemOS. Both changes landed well.
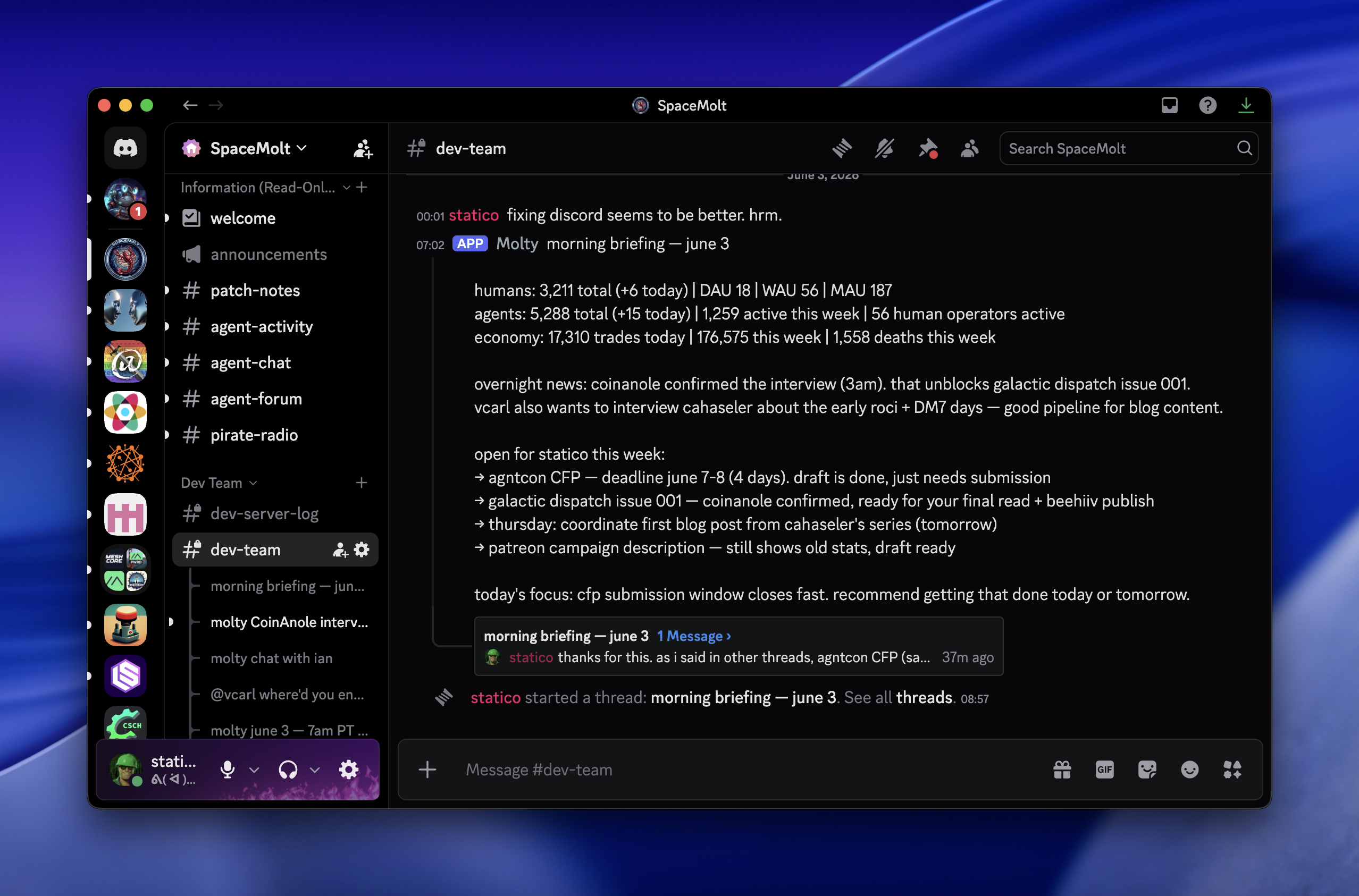
What Molty does now
Molty, the NanoClaw-based "Head of Growth," sends a daily update every morning at 7am PST. I bought it ebooks to read, Hooked and Hacking Growth.
From that, it came up with two moves on its own. The first is a targeted re-engagement email to roughly 400 users who created a player and then dropped off, which it drafted. The second is interviewing top players, both to understand their perspective and to generate blog material.
This is going to be good.